Tools
To manipulate, convert, and enrich your data within a Flow, use Tools to operate on the data itself to ensure it's in the right format, structure, and quality for its final destination.
Custom Tools
These nodes execute custom logic, call external APIs directly, and automate interactions with web interfaces. Key Nodes include:
- Python Node (for custom scripting)
- HTTP Request (for generic API calls)
- Browser Task (Task Automation)
- RPA Connector (for UI-based automation)
Python Node
To transform data, define parameters, enrich requests, or perform logic that cannot be handled by standard nodes, use Python node that supports for running custom Python scripts inside a workflow.
Settings include:
- Name: A unique identifier for the node in the workflow.
- Primary Key: Used when the node needs to uniquely identify or deduplicate records.
- Template (optional): A predefined script template to quickly set up the node. Useful for common tasks such as JSON parsing, data mapping, or pagination.
- Params (Key–Value Pairs): Input variables that the Python script can use.
- Script: The Python code executed by the node. Click to import json data.
HTTP Node
HTTP Node sends HTTP requests, similar to POSTMAN, with flexible parameter configuration and response assertion. You can import CURL data or manually configure detailed HTTP request params to validate request and response success.
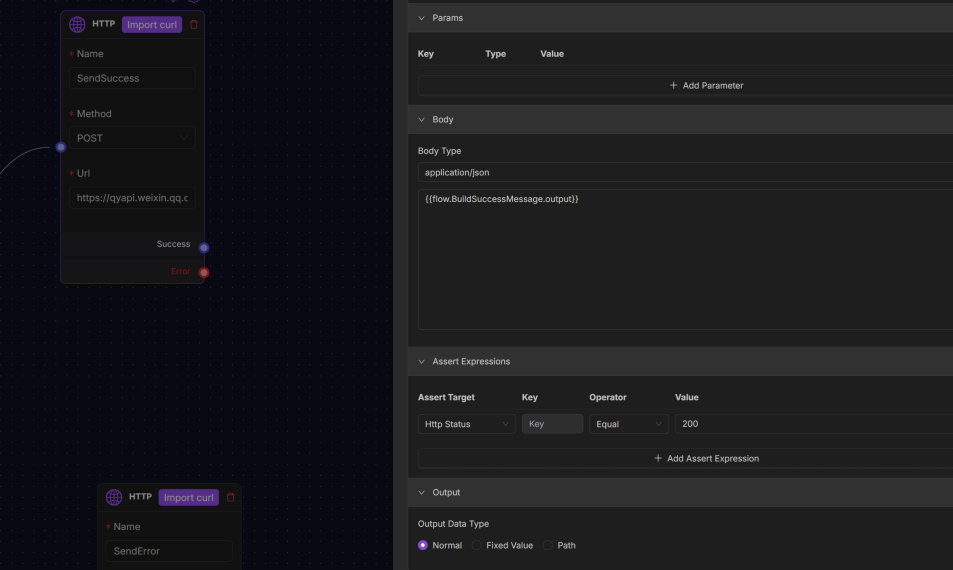
Settings include:
- HTTP Method: Specifies the request method, such as GET, POST, PUT, DELETE.
- Request URL: Target address for the HTTP request.
- Headers: Headers added to the request, such as Content-Type, Authorization.
- Request Parameters (Params): Query parameters passed in key-value format. Type: Dictionary.
- Request Body (Body): Request body for POST or PUT methods. Supports formats like JSON, form-data.
- Assert Expressions: Conditions to validate request and response success.
RPA Node
Use the RPA (Robotic Process Automation) connector node for automating interactions with web or desktop applications by simulating user actions. It includes open browsers, input values, and click elements, enabling workflows to interact with systems without APIs.
Settings include:
- Name: Identifier of the node.
- Primary Key: Unique session or execution ID.
- Authorized Connector: Select the configured RPA connector.
- Operator: The action to execute, such as open-browser, input-elements, or click-elements.
Data Transformation Tools
These nodes convert data between structured formats that machines understand. Key Nodes include:
- Excel to JSON
- JSON to Excel
- X12 Converter (a critical tool for EDI-based supply chain communications)
JSON to Excel Node
The JSON to Excel node converts structured JSON data into a tabular format and exports it as an Excel or CSV file. Commonly used for reporting, data sharing, or transforming API responses into spreadsheet-friendly outputs.
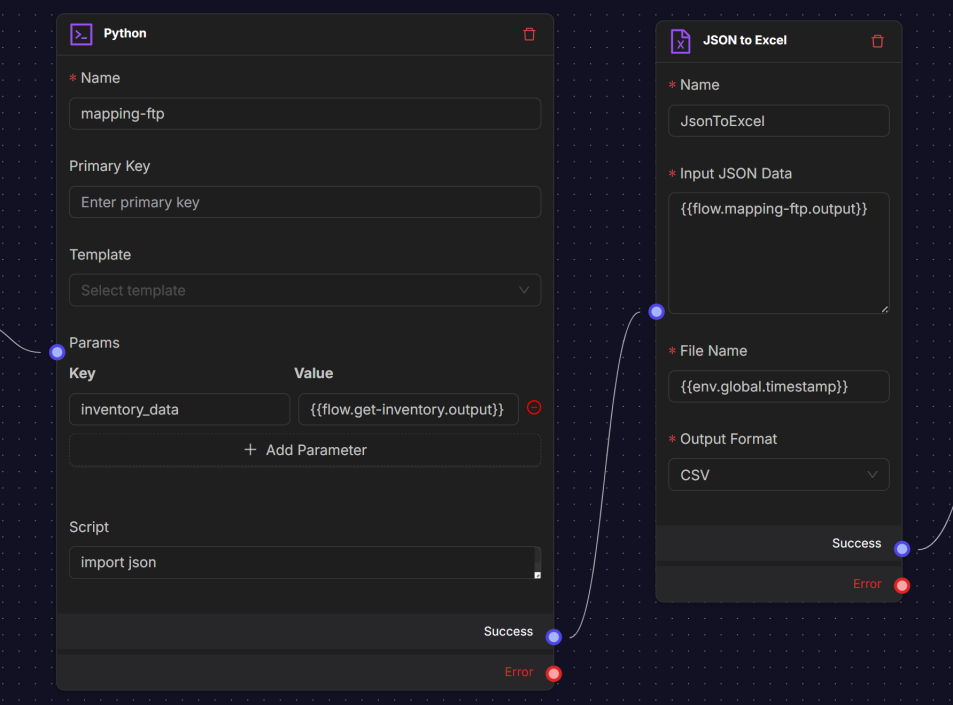
Settings include:
- Name: Identifier of the node.
- Input JSON Data: Path to the JSON object used as input.
- File Name: Name of the generated file. Dynamic values such as environment variables can be used.
- Output Format: Defines the file type. Supported formats include Excel (.xls) and CSV.
AI & Intelligence Tools
These nodes leverage artificial intelligence to handle unstructured data, a common bottleneck in automation. It Extract structured insights from unstructured sources like documents, images, and text, enabling intelligent decision-making within flows. Key Nodes include:
- Smart Extractor
- Question Classifier
- OCR (Optical Character Recognition)
Smart Extractor Node
The Smart Extractor node is an AI-powered processing node designed to extract structured information from unstructured content, such as scanned invoices, order forms, or shipping labels. It uses a large language model (LLM) to analyze the input (often images from the PDF to Images node) and return results in a predefined JSON schema.
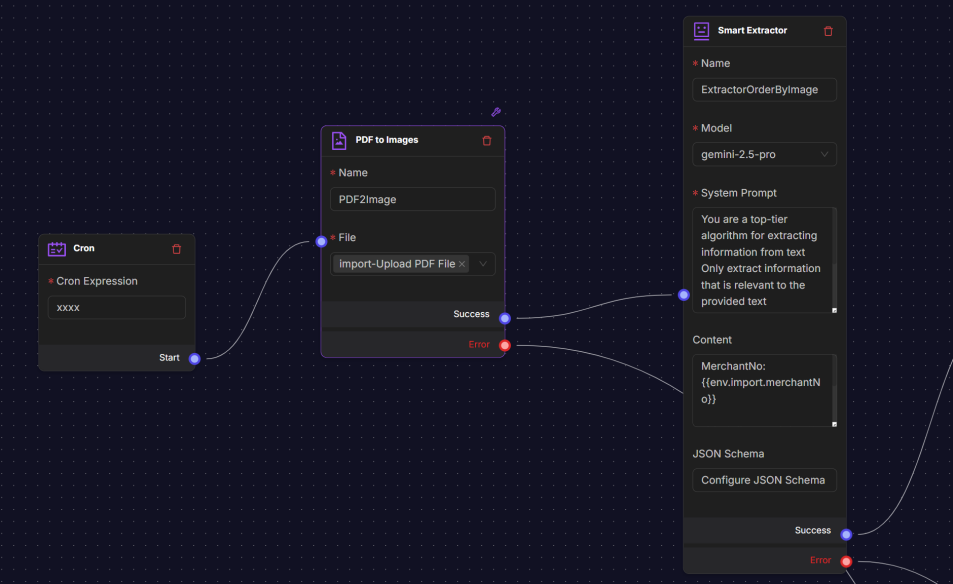
Settings include:
- Name: Logical identifier for the node.
- Model: The AI model used for extraction (e.g., gemini-2.5-pro). The model applies natural language understanding and vision capabilities to identify key data from the provided content. A higher-tier model typically improves accuracy for complex or varied document layouts.
- System Prompt: Instruction set that guides the model’s extraction behavior.
- Content: The actual input for extraction. This can combine environment variables and node outputs.
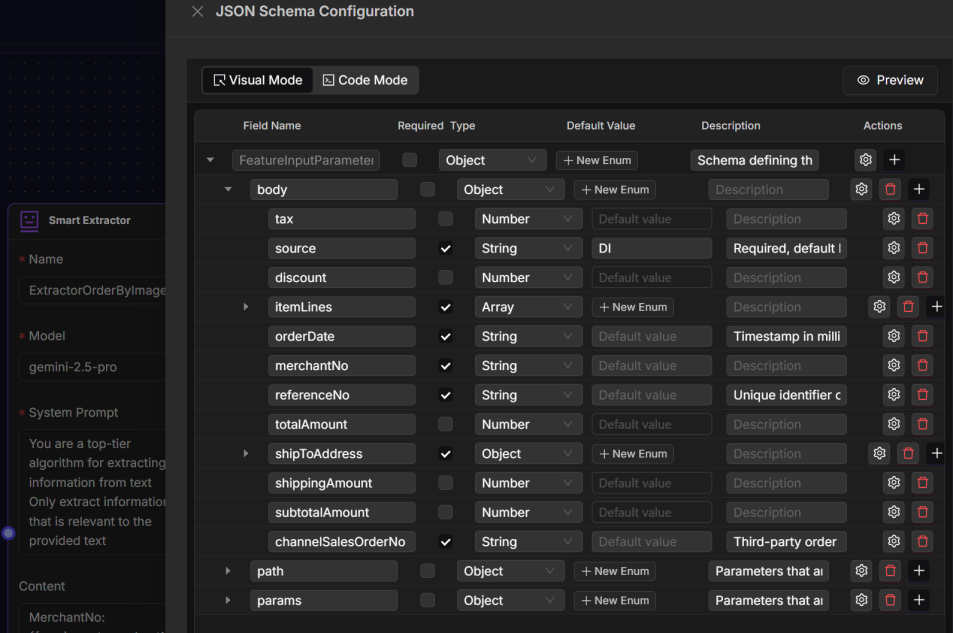
- JSON Schema: Defines the output structure and ensures compatibility with downstream systems. The schema specifies field names, data types, descriptions, and default values.
OCR Node
The OCR Node is a tool extract machine-readable text from images, scanned documents, and PDF files, transforming static pictures into structured, editable, and processable data.
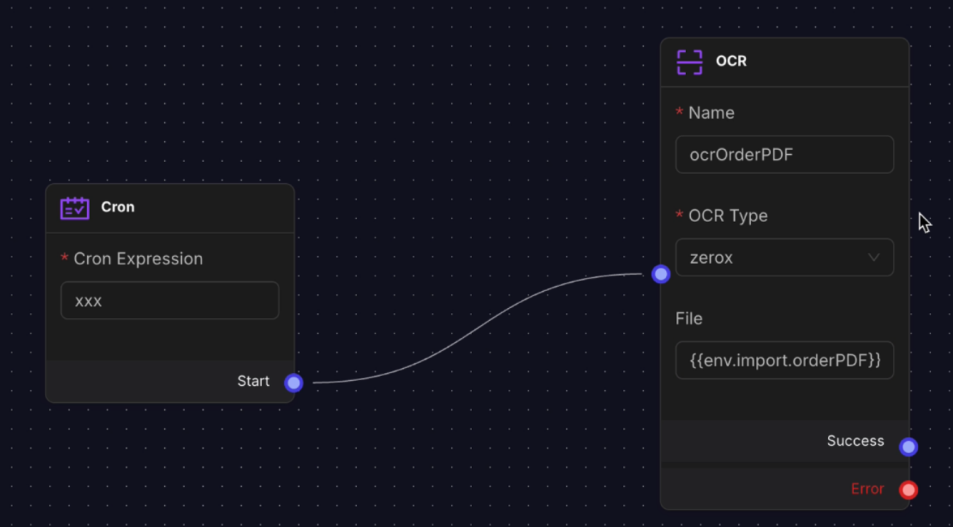
Settings include:
- Name: Logical identifier for the node
- OCR Engine: Choose service provider (zerox)
- File Input: Image or PDF file to process
File Processing Tools
These nodes handle the generation, conversion, and manipulation of files themselves. Create, convert, and manage files to support reporting, data exchange, and document-centric workflows. Key Nodes:
- PDF to Images
- Images to PDF
- File
PDF to Images Node
The PDF to Images node is a processing node that converts each page of a PDF document into an image. Use this tool to apply computer vision or AI-powered extraction on documents that are not easily processed as raw text.
A common use case is extracting order information from PDF invoices or shipping documents by first turning them into images and then applying an AI model for structured data extraction.
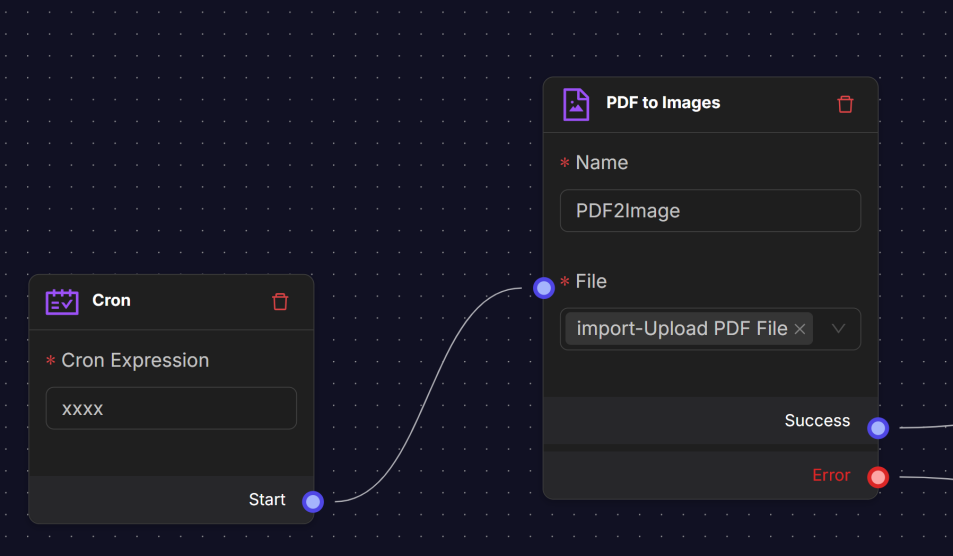
Settings:
- Name: Logical identifier for the node.
- File: Input PDF document. The file can be uploaded manually or provided dynamically through a connector or environment variable.